Version Française
QLearning
The QLearning algorithm is one of the many methods of reinforcement learning. It is an interesting one because, since its principle is very simple, it is the easiest to implement.The difficulty of this project was not how to implement it, rather it was what to use it for and how to represent its parameters.
Group: Alexandre LHUILLIER (FIPA 2) - Pascal NUNES (FIP 15)
Explanation
Reinforcement learning is a way to teach an agent the best policy to execute its task. The agent has a finite set of actions and a set of states. Its goal is to figure, for each state, the most fitting action. To reach this goal, each time it executes an action, its environment must be able to send it a feedback about its action, which means either a reward or a penalty.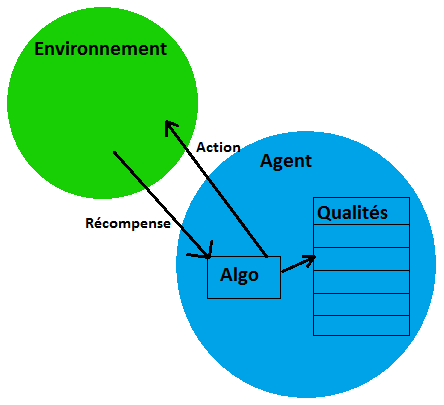
We can see the agent as a robot, capable of a finite set of actins and owning a list of "Qualities". It is always doing an action; when this action has a consequence either on it or its environment, the environment sends back a reward (or a penalty). The agent computes the quality value of the action it just did. During the first iterations, the only actions that have an effect on the computations are the ones that provoke an immediate reward. After a large number of iterations, the agent will be able to know the sequence of actions that lead it to a better reward. The computation doesn’t only take into account the immediate reward of the action, but also the quality of the best next action.
With
- s as the current state of the agent
- s’ the next state
- a its current action
- a’ its next action
- α a learning coefficient
- r the reward of the current (state, action) couple
- τ a refresh coefficient
- Q(s, a) and Q(s’, a’) the "qualities" of, respectively, the current and next (state, action) couple. maxQ(s’, a’) represents the quality of the best action for state s’.
The quality of an action is computed this way:
Examples
- QLearning implementations:
- Applet showcasing the algorithm:
http://thierry.masson.free.fr/IA/fr/qlearning_apropos.htm - The one-armed robot that learns how to go forward:
http://www.applied-mathematics.net/qlearning/qlearning.html
- Applet showcasing the algorithm:
- Reinforcement learning in general:
- Robots that learn how to dribble:
http://www.youtube.com/watch?v=nM1HTp_p3ly
- Robots that learn how to dribble:
Our application
Our goal
If you tried Thierry Masson’s or similar demos - where a robot moves on a grid - , they never need to go back on their steps: they stop as soon as they reach a reward.
We wanted to go further, by allowing a robot to go back on its steps, for example to get a reward one side of a corridor then go back and reach the labyrinth’s exit on the other side.



To get the best possible reward, the agent must get as many rewards as possible, walking back on its steps if needed
The implémentation
To get to this result, we had to rethink how we represent a state. While in the above examples, they are represented by their position on the grid, a state in our implementation is defined by:- Its coordinates on the grid
- The list of "mobile" objects still present on the map
This approach has a drawback: the state count depends on the number of mobile objects on the map. For example, on a 10 by 10 map with 4 hearts inside, the number of states the agent might explore is 10*10*(4+6+4+1+1)=1600.(The area of the map multiplied by every possible combination of hearts on the map?). Moreover, depending on the map’s layout, backtracking isn’t always necessary. More details to come
The software
The working application:
Our Java implementation
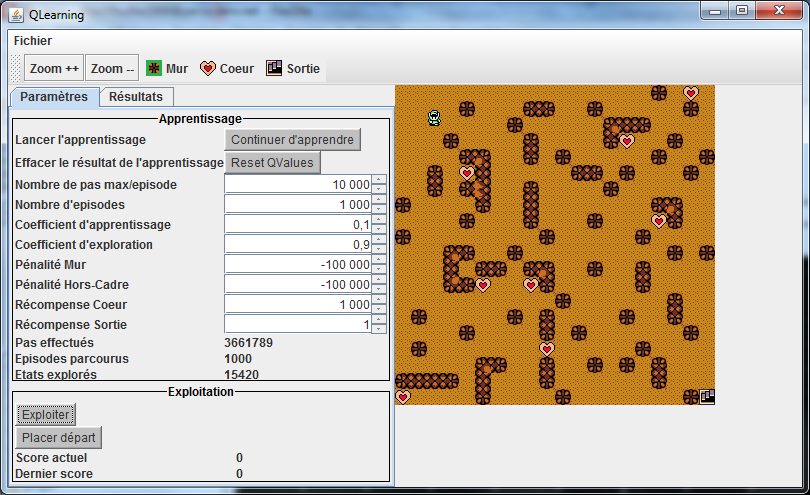
With the left toolbar, you can:
- Start learning
- Reset all learning data
- Change the reward value for every type of object
- Change the max number of episodes before learning is considered finished
- Start an exploitation
- Change the starting position of the robot
With the top toolbar, you can:
- Zoom/Unzoom the map
- Choose what kind of object to drop on the map.
After you chose a kind of object, you can drop it on the map by clicking on a tile. You can remove an object on the map by right-clicking on it.
Be careful when dropping hearts: as stated above, the more hearts on the map, the bigger count of possible states, therefore learning can get longer and eat much more RAM.
Sources might be available later.
Bonus
A completely different application: two agents learn how to fight each other with a saber.They have 5 possible actions:
- go forward
- go backward
- attack
- parry
- wait
Their state is represented by the distance between them and their opponent, and the current pose of the opponent.
Therefore, the number of possible states is fixed and can be represented by a 2-Dimensional array, like a grid, but for a completely different result.
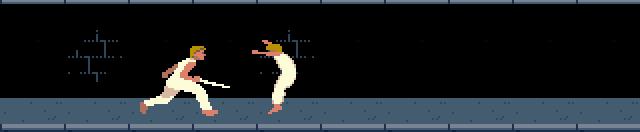
In the "vitesse"(speed) dropdown list, choose "10x" to speed up learning.
Push "Apprendre"("Learn").
After a few minutes, push "Stopper apprentissage"("Stop learning").
Put speed back to "1x".
Push "Exploiter" to appreciate the results of the learning.
With the buttons "Remplacer"("Replace") in the "Agent de gauche" et "Agent de droite" menus("Left Agent" and "Right Agent"), you can control directly one of the agents with these keyboard keys:
- Left and Right arrows to go backwards or forward
- Up Arrow to attack
- Down Arrow to parry
Will the man be stronger than the machine?