English Version
Le QLearning
Le QLearning est l’un des algorithmes d’apprentissage par renforcement. Elle est intéressante car, étant assez bestiale dans son principe, c’est la plus simple à implémenter.La difficulté du projet ne se situait pas dans son implémentation à proprement parler, mais dans le choix d’une application et dans la représentation de ses paramètres.
Binôme: Alexandre LHUILLIER (FIPA 2) - Pascal NUNES (FIP 15)
Explication
L’apprentissage par renforcement est une technique permettant d’apprendre à un agent la meilleure politique lui permettant d’exécuter une tâche. L’agent a à sa disposition un ensemble d’actions fini et un ensemble d’états. Son but est de trouver, pour chaque état, la meilleure action à effectuer. Pour cela, à chaque fois qu’il effectue une action, son environnement doit être capable de lui renvoyer un feedback sur son action, à savoir soit une récompense, soit une pénalité.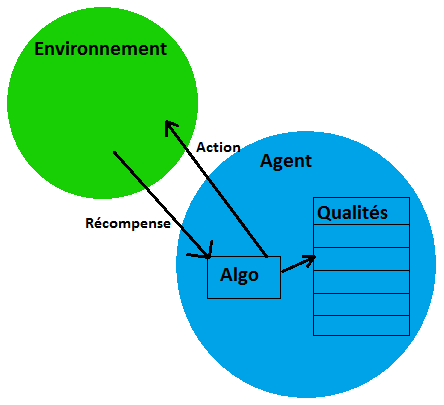
On peut considèrer l’agent comme un robot, capable d’un nombre fini d’actions et dôté d’une liste de "Qualités". Il effectue en permanence des actions; quand celle-ci a une conséquence sur lui ou son environnement, ce dernier lui renvoie une récompense (ou une pénalité). L’agent calcule à chaque fois la qualité de l’action qu’il vient d’effectuer. Dans les premières itérations, seules les actions qui rapportent aussitôt une récompense ont une incidence sur le calcul. Avec un grand nombre d’itérations, l’agent pourra déduire la suite d’actions qui le mène à une bonne récompense. En effet, le calcul prend en compte non seulement la récompense immédiate, mais aussi la qualité de la meilleure action suivante.
Avec
- s l’état courant de l’agent
- s’ l’état suivant
- a son action courante
- a’ son action suivante
- α un coefficient d’apprentissage
- r la récompense associée au couple (état, action) courant
- τ un coefficient d’actualisation
- Q(s, a) et Q(s’, a’) les "qualités" respectivement du couple (état, action) courant et suivant. maxQ(s’, a’) représente la qualité de la meilleure action dans l’état s’.
la qualité d’une action se calcule de la manière suivante:
Des exemples
- Implémentations du QLearning:
- Applet de démonstration de l’algorithme:
http://thierry.masson.free.fr/IA/fr/qlearning_apropos.htm - Le robot à un bras qui apprend à avancer:
http://www.applied-mathematics.net/qlearning/qlearning.html
- Applet de démonstration de l’algorithme:
- L’apprentissage par renforcement en général:
- Des robots qui apprennent à dribbler:
http://www.youtube.com/watch?v=nM1HTp_p3ly
- Des robots qui apprennent à dribbler:
Notre application du QLearning
Notre but
Si vous avez essayé la démo de Thierry Masson ou d’autres exemples du même style - où un robot évolue sur un quadrillage - , ils n’ont jamais besoin de retourner sur leurs pas. En effet, leur parcours s’arrête dès qu’ils atteignent une récompense.
Nous avons voulu aller plus loin, en permettant à un robot de pouvoir revenir sur ses pas, par exemple pour récupérer une récompense d’un côté d’un couloir puis faire demi-tour pour rejoindre la sortie du labyrinthe qui serait de l’autre côté du couloir.



Pour obtenir la meilleure récompense possible, l’agent doit récupérer le maximum de récompenses, si nécessaire en retournant sur ses pas
L’implémentation
Pour parvenir à ce résultat, nous avons du repenser notre représentation d’un état. Alors que dans les exemples sus-cités, il sont simplement représentés par leurs coordonnées sur le quadrillage, un état dans notre implémentation se définit par:- Ses coordonnées sur le quadrillage
- La liste des objets "mobiles" encore présents sur la carte
Cette approche a un défaut: le nombre d’états dépend du nombre d’objets mobiles sur la carte. Par exemple, sur une carte de 10 cases de largeur et 10 cases de hauteur où 4 coeurs sont disséminés, le nombre d’états que l’agent peut potentiellement explorer est 10*10*(4+6+4+1+1)=1600.(l’aire de la carte multipliee par toutes les combinaisons possibles de coeurs sur la carte?). De plus, selon la configuration de la carte, des allers-retours ne sont pas toujours nécessaires. Plus de détails à venir
Le programme
À tester:
Notre implémentation en java
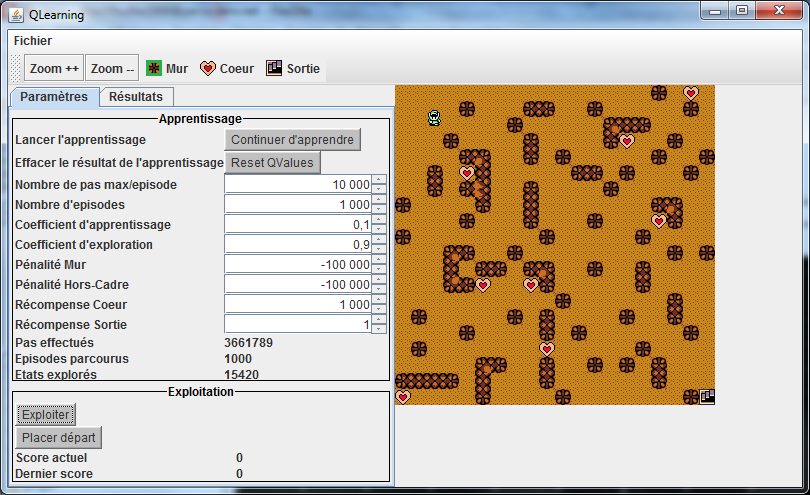
Avec la barre d’outils de gauche, vous pouvez:
- Lancer un apprentissage
- Réinitialiser les connaissances apprises
- Paramétrer les récompenses pour une rencontre avec chaque type d’objet
- Paramétrer le nombre d’épisodes à atteindre pour terminer un apprentissage
- Lancer une exploitation des connaissances apprises
- Changer le point de départ du robot
Avec la barre d’outils du haut, vous pouvez:
- Zoomer/dézoomer sur la carte
- Choisir un type d’objet à placer sur la carte.
Une fois que vous avez choisi un type d’objet à placer, vous pouvez le placer sur la carte en cliquant sur une de ses cases. Vous pouvez supprimer un objet de la carte en cliquant dessus avec le bouton droit de la souris.
Attention en plaçant des coeurs: comme mentionné précédemment, plus il y en a sur la carte, plus le nombre potentiel d’états est grand, et donc plus l’apprentissage peut être long et la consommation mémoire élevée.
Les sources seront éventuellement disponibles plus tard.
Bonus
Une application totalement différente: deux agents qui apprennent à se combattre au sabre.Ils disposent de 5 actions:
- avancer
- reculer
- attaquer
- parer
- attendre
Leur état est représenté par la distance qui les sépare de leur adversaire et la position actuelle de leur adversaire.
Le nombre d’états possibles est donc fixe et peut se représenter par un tableau à 2 dimensions, de la même façon que pour un quadrillage, mais pour un résultat totalement différent.
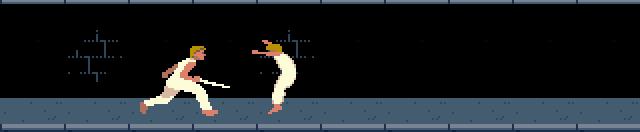
Dans la liste déroulante "vitesse", choisissez "10x" pour accélérer l’apprentissage.
Appuyez sur le bouton "Apprendre".
Après quelques minutes, appuyez sur "Stopper apprentissage".
Remettez la vitesse à "1x".
Appuyez sur "Exploiter" pour apprécier le résultat de l’apprentissage.
Avec les boutons "Remplacer" dans les menus "Agent de gauche" et "Agent de droite", vous pouvez contrôler vous-même l’un des deux agents avec les commandes suivantes:
- Les flèches gauche et droite pour avancer ou reculer
- La flèche haut pour attaquer
- La flèche bas pour parer
L’homme sera-t-il plus fort que la machine?